Как автоматизировать сбор отзывов с маркетплейсов: пошаговая инструкция с анализом и отчётами
Содержание статьи
- Введение
- Предварительная подготовка
- Базовые понятия
- Шаг 1: выбор источников и юридические рамки
- Шаг 2: подготовка окружения и установка инструментов
- Шаг 3: проектирование схемы данных и файлов
- Шаг 4: базовый парсер отзывов (http запросы)
- Шаг 5: работа с динамическими страницами (безголовый браузер)
- Шаг 6: ротация прокси, заголовков и ограничение скорости
- Шаг 7: очистка, нормализация и устранение дублей
- Шаг 8: ai‑анализ тональности (sentiment) и темы жалоб
- Шаг 9: отчёты и метрики: csv, сводки и ключевые графики
- Шаг 10: автоматизация и расписание задач
- Проверка результата
- Типичные ошибки и решения
- Дополнительные возможности
- Faq
- Заключение
Введение
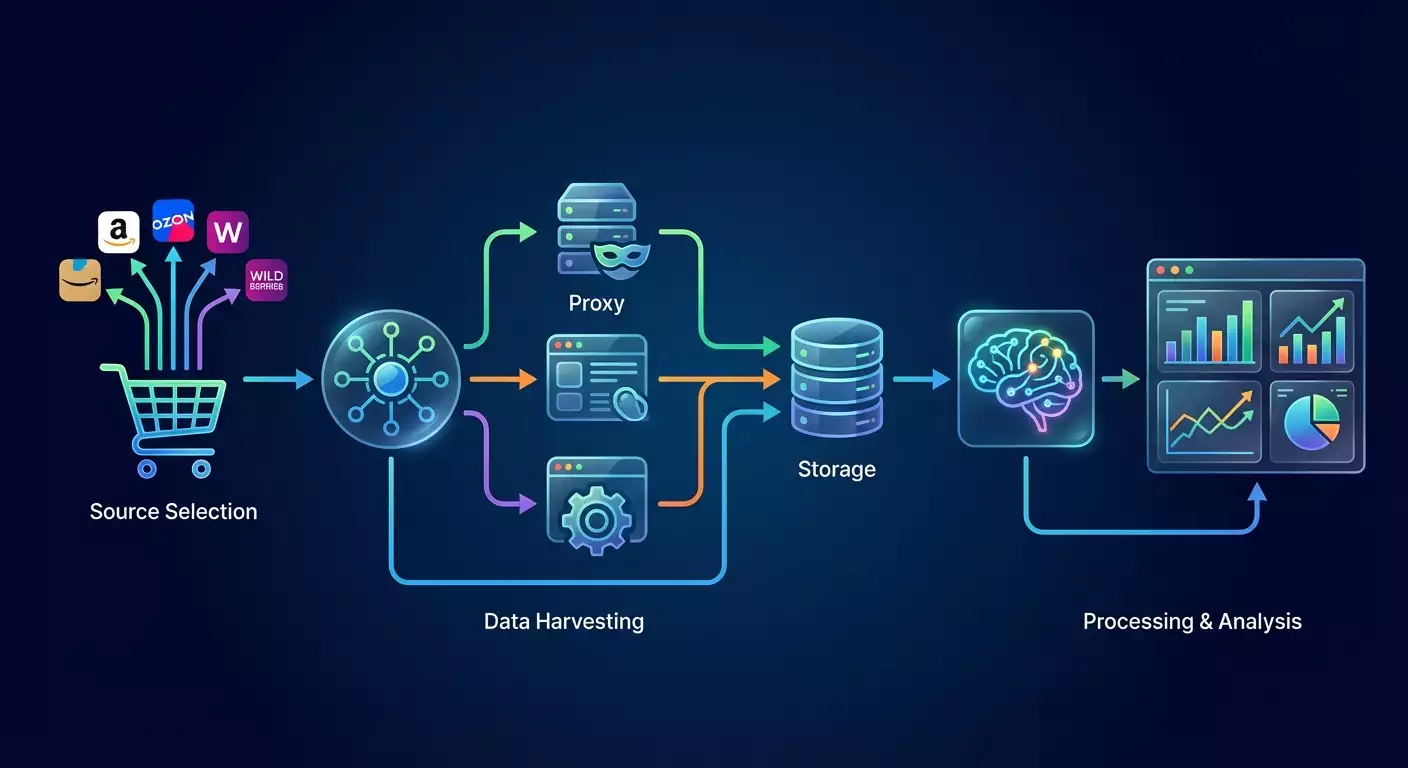
В этом пошаговом гайде вы настроите полностью автоматизированный процесс сбора отзывов с маркетплейсов, их очистку, структурирование, анализ тональности с помощью AI и формирование простых отчётов. Вы получите готовые командные примеры, рабочую структуру проекта, проверочные чек-листы и рекомендации по масштабированию. Мы используем простые инструменты, чтобы вы могли добиться результата без опыта программирования. Важно: мы действуем легально и этично, учитывая правила площадок и ограничения по нагрузке.
Этот гайд для специалистов по маркетингу, продавцов на маркетплейсах, аналитиков, владельцев брендов и начинающих разработчиков. Ничего сложного: мы объясняем каждое действие простым языком. При желании вы сможете углубиться в продвинутые настройки, повысить стабильность и скорость, а также подключить дашборды.
Что нужно знать заранее: базовая работа с компьютером, установка программ, понимание файлов и папок. Полезно, но не обязательно: начальные знания Python. Мы покажем команды и объясним каждую.
Сколько времени потребуется: на базовую настройку и первые результаты от 3 до 6 часов. На полноценную автоматизацию с планировщиком, прокси и аналитикой 1–2 дня. Это реальная оценка для новичка.
Предварительная подготовка
Необходимые инструменты и доступы: компьютер с Windows, macOS или Linux; подключение к интернету; Python 3.10 или выше; пакетный менеджер pip; учётная запись на маркетплейсах (если нужен доступ к персональным данным и API); при необходимости доступ к прокси‑провайдеру. Будем использовать библиотеку для HTTP запросов, лёгкую базу данных SQLite и AI для анализа тональности.
Системные требования: 4 ГБ ОЗУ минимум; 2 ГБ свободного места на диске; доступ к установке Python пакетов; стабильный интернет. Для ускорения AI‑аналитики желательно 8 ГБ ОЗУ. GPU не требуется, но ускорит анализ.
Что нужно скачать и установить: Python 3.10+; инструменты командной строки (в Windows используйте PowerShell); библиотеки requests, httpx или aiohttp; для AI анализа transformers и torch; для обработки данных pandas. Мы дадим точные команды установки на этапе инструкции.
Создание резервных копий: если вы уже ведёте базу отзывов, перед началом сделайте копию вашей текущей базы данных и файлов с исходными отзывами. Сохраните в отдельную папку с датой. Это поможет откатиться при ошибках.
⚠️ Внимание: Прежде чем собирать отзывы, изучите условия использования выбранных маркетплейсов. Убедитесь, что вы не нарушаете их правила, используете допустимую частоту запросов и не собираете персональные данные, которые нельзя обрабатывать без согласия.
Базовые понятия
Ключевые термины простым языком: парсинг — это автоматическое получение данных со страниц. Прокси — посредник для сетевых запросов; помогает распределить трафик и маскировать ваш настоящий IP адрес. Ротация прокси — автоматическая смена прокси между запросами. Sentiment‑анализ — определение эмоциональной окраски текста: позитивный, нейтральный или негативный. ETL — извлечение, преобразование и загрузка данных в хранилище.
Принцип работы нашей системы: вы выбираете источники отзывов, настраиваете аккуратный сбор данных с ограничением скорости, очищаете и приводите отзывы к единому формату, сохраняете их в базу и запускаете AI для анализа тональности. Дальше вы строите сводки: динамика оценок, проблемные темы, частота негативных упоминаний. Всё это автоматизируется планировщиком.
Что важно понимать перед началом: некоторые страницы подгружают отзывы динамически. В таких случаях нужен безголовый браузер, например Playwright. Часть площадок предоставляет публичные API для отзывов — это надёжнее и быстрее. Начните с официальных API, если они доступны. Где их нет, аккуратно используйте парсинг с учётом легальных ограничений и вежливого режима.
Шаг 1: Выбор источников и юридические рамки
Цель
Определить конкретные карточки товаров или магазины, откуда вы будете получать отзывы, и проверить, можно ли их собирать согласно правилам площадки.
Пошаговая инструкция
- Составьте список маркетплейсов, где есть ваши товары. Пример: маркетплейс А (страницы товара), маркетплейс Б (страницы магазина).
- Для каждого источника определите URL страниц отзывов. Обычно это вкладка Отзывы в карточке товара.
- Проверьте условия использования и robots.txt площадки. Узнайте частотные лимиты и разрешения.
- Решите, будете ли использовать официальный API. Если есть открытая документация и ключ, это лучше.
- Определите объём: сколько товаров, с какой периодичностью обновлять. Пример: 500 товаров, обновление раз в сутки.
- Выберите формат хранения: CSV для начала или база SQLite для автоматизации.
Важные моменты: не собирайте закрытые и персональные данные. Уважайте частоту запросов. Старайтесь не перегружать площадку.
Совет: начните с 5–10 карточек, отладьте процесс и только потом масштабируйте.
✅ Проверка: у вас есть таблица или документ со списком URL страниц отзывов, частотным планом и пометкой, можно ли парсить легально.
Возможные проблемы: URL вкладки отзывов недоступен напрямую. Решение: откройте карточку товара и найдите параметр, который подгружает отзывы через запрос к API. Это видно в инструментах разработчика браузера в разделе Сеть.
Шаг 2: Подготовка окружения и установка инструментов
Цель
Создать рабочую папку проекта, установить Python пакеты и проверить, что всё запускается.
Пошаговая инструкция
- Создайте папку проекта, например C:/reviews_automation или ~/reviews_automation.
- Откройте терминал в этой папке.
- Создайте виртуальное окружение Python. Команда для Windows PowerShell: python -m venv .venv; для macOS и Linux: python3 -m venv .venv.
- Активируйте окружение. Windows: .venv\Scripts\Activate.ps1; macOS/Linux: source .venv/bin/activate.
- Установите основные библиотеки. Выполните: pip install requests httpx beautifulsoup4 lxml pandas tqdm.
- Для AI анализа установите: pip install torch --index-url https://download.pytorch.org/whl/cpu и затем pip install transformers sentencepiece.
- Для динамических страниц при необходимости установите Playwright: pip install playwright и затем python -m playwright install chromium.
Важные моменты: используйте виртуальное окружение, чтобы изолировать зависимости проекта.
Совет: если установка torch идёт медленно, оставьте окно открытым и дождитесь завершения. Это нормальная ситуация без ошибки.
✅ Проверка: введите python -c "import requests, pandas, transformers; print('ok')". Должно напечатать ok.
Возможные проблемы: конфликт версий. Решение: обновите pip командой pip install --upgrade pip и повторите установку.
Шаг 3: Проектирование схемы данных и файлов
Цель
Согласовать единый формат хранения отзывов для разных маркетплейсов и подготовить минимальную базу.
Пошаговая инструкция
- Определите поля отзыва: marketplace, product_id, review_id, rating, title, body, pros, cons, author, verified, created_at, region, helpful_count, seller_reply, url, scrape_ts, source_raw.
- Выберите хранилище: для начала используйте SQLite файл reviews.db.
- Создайте таблицу отзывов через Python одной командой: python -c "import sqlite3; c=sqlite3.connect('reviews.db'); c.execute('create table if not exists reviews (marketplace text, product_id text, review_id text primary key, rating int, title text, body text, pros text, cons text, author text, verified int, created_at text, region text, helpful_count int, seller_reply text, url text, scrape_ts text, source_raw text)'); c.commit(); c.close(); print('db ready')".
- Подготовьте папку data для JSON и CSV экспорта: создайте папку data.
- Подготовьте файл с источниками source_list.csv. Содержание: marketplace,product_id,url. Заполните 5–10 строками.
Важные моменты: поле review_id должно быть уникальным, чтобы исключить дубликаты.
Совет: добавьте индекс по полям product_id и created_at для ускорения аналитики. Команда: python -c "import sqlite3; c=sqlite3.connect('reviews.db'); c.execute('create index if not exists idx_product_date on reviews(product_id, created_at)'); c.commit(); c.close(); print('indexed')".
✅ Проверка: убедитесь, что в папке появился файл reviews.db и команда вывела db ready. Индекс создался без ошибок.
Возможные проблемы: ошибка доступа к файлу на Windows. Решение: закройте все программы, которые используют файл, и повторите команду.
Шаг 4: Базовый парсер отзывов (HTTP запросы)
Цель
Собрать отзывы с простых источников, где контент доступен без сложной динамики, и сохранить их в базу.
Пошаговая инструкция
- Создайте базовый однофайловый скрипт для загрузки страниц и извлечения отзывов. Выполните команду: echo import sys,requests,bs4,json,sqlite3,datetime,random,time; from bs4 import BeautifulSoup; import lxml; import hashlib; import pandas as pd; import argparse; ap=argparse.ArgumentParser(); ap.add_argument('--url'); ap.add_argument('--marketplace'); ap.add_argument('--product'); ap.add_argument('--ua',default='Mozilla/5.0'); ap.add_argument('--delay',type=float,default=1.0); args=ap.parse_args(); s=requests.Session(); s.headers.update({'User-Agent':args.ua}); r=s.get(args.url,timeout=30); html=r.text; soup=BeautifulSoup(html,'lxml'); # Пример извлечения, адаптируйте селекторы под ваш источник; reviews=[]; cards=soup.select('[data-review]') or soup.select('.review') or []; now=datetime.datetime.utcnow().isoformat(); conn=sqlite3.connect('reviews.db'); for i,card in enumerate(cards): rating_el=card.select_one('[data-rating]') or card.select_one('.rating') or None; rating=int(rating_el.get('data-rating',5)) if rating_el else 0; title_el=card.select_one('.title') or None; title=title_el.get_text(strip=True) if title_el else ''; body_el=card.select_one('.body') or card.select_one('.review-text') or None; body=body_el.get_text(' ',strip=True) if body_el else ''; author_el=card.select_one('.author') or None; author=author_el.get_text(strip=True) if author_el else 'unknown'; date_el=card.select_one('time') or card.select_one('.date') or None; created_at=date_el.get('datetime','') if date_el and date_el.has_attr('datetime') else (date_el.get_text(strip=True) if date_el else ''); rid=hashlib.md5((author+created_at+body).encode()).hexdigest(); url=args.url; conn.execute('insert or ignore into reviews (marketplace,product_id,review_id,rating,title,body,pros,cons,author,verified,created_at,region,helpful_count,seller_reply,url,scrape_ts,source_raw) values (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)',(args.marketplace,args.product,rid,rating,title,body,'','',author,0,created_at,'',0,'',url,now,'')); conn.commit(); conn.close(); print(f'parsed {len(cards)} reviews') > scraper_basic.py
- Запустите сбор для одного URL. Пример: python scraper_basic.py --marketplace=demo --product=SKU123 --url="https://пример-страницы-отзывов" --delay=1.0.
- Проверьте базу данных. Команда: python -c "import sqlite3; c=sqlite3.connect('reviews.db'); print(c.execute('select count(*) from reviews').fetchone()[0]); c.close()".
Важные моменты: селекторы .review, .title, .body — примеры. Вам нужно адаптировать их под ваш маркетплейс, изучив HTML структуры вкладки отзывов.
Совет: откройте страницу в браузере, нажмите правой кнопкой на текст отзыва, выберите Просмотреть код. Найдите класс контейнера отзыва. Подставьте его в селектор.
✅ Проверка: в терминале вы увидите parsed N reviews, а в базе появятся записи.
Возможные проблемы: отзывы подгружаются через JS и не видны в HTML. Решение: используйте Шаг 5 с Playwright или найдите XHR запрос в инструментах разработчика.
Шаг 5: Работа с динамическими страницами (безголовый браузер)
Цель
Собирать отзывы, которые подгружаются динамически, используя безголовый браузер и имитацию действий пользователя.
Пошаговая инструкция
- Создайте скрипт на Playwright. Команда: echo import sys,json,sqlite3,datetime,random,time,argparse; from playwright.sync_api import sync_playwright; import hashlib; ap=argparse.ArgumentParser(); ap.add_argument('--url'); ap.add_argument('--marketplace'); ap.add_argument('--product'); ap.add_argument('--pages',type=int,default=1); ap.add_argument('--ua',default='Mozilla/5.0'); args=ap.parse_args(); now=datetime.datetime.utcnow().isoformat(); with sync_playwright() as p: b=p.chromium.launch(headless=True); ctx=b.new_context(user_agent=args.ua, locale='ru-RU'); page=ctx.new_page(); all_cards=[]; page.goto(args.url,wait_until='domcontentloaded'); time.sleep(2.0); for i in range(args.pages): cards=page.query_selector_all('[data-review], .review'); all_cards.extend(cards); next_btn=page.query_selector('button[aria-label="Следующая"], .next, [data-next]'); # адаптируйте; 0 if not next_btn else next_btn.click(); time.sleep(1.5); conn=sqlite3.connect('reviews.db'); for el in all_cards: txt=el.inner_text(); rating_el=el.query_selector('[data-rating], .rating'); rating=int(rating_el.get_attribute('data-rating')) if rating_el and rating_el.get_attribute('data-rating') else 0; title_el=el.query_selector('.title'); title=title_el.inner_text().strip() if title_el else ''; body=txt.strip(); rid=hashlib.md5((title+body).encode()).hexdigest(); conn.execute('insert or ignore into reviews (marketplace,product_id,review_id,rating,title,body,pros,cons,author,verified,created_at,region,helpful_count,seller_reply,url,scrape_ts,source_raw) values (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)',(args.marketplace,args.product,rid,rating,title,body,'','','unknown',0,'','','0','',args.url,now,'')); conn.commit(); conn.close(); b.close(); print(f'parsed {len(all_cards)} reviews') > scraper_dynamic.py
- Запустите сбор: python scraper_dynamic.py --marketplace=demo --product=SKU123 --url="https://пример-страницы-отзывов" --pages=3.
- Проверьте количество записей в базе, как в предыдущем шаге.
Важные моменты: селекторы кнопки Следующая и блоков отзывов обязательно адаптируйте под ваш интерфейс. Иногда кнопка пагинации представлена стрелкой или другим селектором.
Совет: если пагинация бесконечная (ленивая подгрузка), замените клик на next_btn прокруткой вниз: выполните page.mouse.wheel(0, 3000) в цикле, добавляя паузу.
✅ Проверка: в терминале увидите parsed N reviews. В базе появились новые записи.
Возможные проблемы: сайт блокирует браузер. Решение: установите задержки, настройте user-agent, добавьте контекст с accept_language и viewport. Можно запускать в видимом режиме headless=False для отладки.
Шаг 6: Ротация прокси, заголовков и ограничение скорости
Цель
Снизить риск блокировок, распределяя запросы и имитируя естественную активность.
Пошаговая инструкция
- Подготовьте список прокси от вашего провайдера. Формат: http://user:pass@host:port, разделяйте запятой. Пример: http://u:p@1.2.3.4:8000,http://u:p@5.6.7.8:8010.
- Придумайте пул user-agent строк. Используйте 3–5 популярных браузеров.
- Добавьте параметры в базовый скрипт. Запуск с прокси: python -c "import requests,random; proxies=['http://u:p@1.2.3.4:8000','http://u:p@5.6.7.8:8010']; ua=['Mozilla/5.0','Safari/537.36','Chrome/122']; p=random.choice(proxies); h={'User-Agent':random.choice(ua)}; r=requests.get('https://httpbin.org/ip',headers=h,proxies={'http':p,'https':p},timeout=20); print(r.text)".
- В Playwright настройте контекст с прокси: python -c "from playwright.sync_api import sync_playwright; import random; proxies=['http://u:p@1.2.3.4:8000','http://u:p@5.6.7.8:8010']; with sync_playwright() as p: b=p.chromium.launch(proxy={'server':random.choice(proxies)}); b.close(); print('ok')".
- Добавьте случайные задержки между запросами 1.0–3.5 секунды. Это уменьшает вероятность блокировок.
Важные моменты: храните доступы к прокси в отдельном файле, не публикуйте их. Обновляйте список еженедельно.
⚠️ Внимание: не используйте прокси для обхода платных или закрытых зон. Работайте только с общедоступными страницами согласно правилам площадки.
Совет: поставьте ограничение параллельности. Для HTTP запросов держите не более 2–4 одновременных потоков на один домен.
✅ Проверка: запросы стабильно выполняются, IP адрес меняется при смене прокси, блокировок нет или они редки.
Возможные проблемы: прокси нестабилен. Решение: внедрите простую стратегию повторов с экспоненциальной паузой и переключением прокси при ошибке соединения.
Шаг 7: Очистка, нормализация и устранение дублей
Цель
Привести отзывы к единому виду, удалить повторы и подготовить данные к аналитике.
Пошаговая инструкция
- Добавьте обязательные поля, если они отсутствуют, и удалите лишние пробелы в тексте. Команда: python -c "import sqlite3; import re; c=sqlite3.connect('reviews.db'); cur=c.cursor(); rows=cur.execute('select review_id, body from reviews').fetchall(); for rid,body in rows: nb=re.sub(r'\s+',' ', body or '').strip(); cur.execute('update reviews set body=? where review_id=?',(nb,rid)); c.commit(); c.close(); print('normalized')".
- Удалите пустые отзывы. Команда: python -c "import sqlite3; c=sqlite3.connect('reviews.db'); c.execute('delete from reviews where body is null or trim(body)=""'); c.commit(); c.close(); print('cleaned')".
- Проверьте дубликаты по review_id. Если вы генерируете review_id через хэш текста, он уже уникален. Иначе добавьте уникальный индекс.
- Сохраните чистую выгрузку в CSV для контроля: python -c "import sqlite3,pandas as pd; c=sqlite3.connect('reviews.db'); df=pd.read_sql_query('select * from reviews',c); df.to_csv('data/reviews_clean.csv',index=False); c.close(); print('exported')".
Важные моменты: обязательно оставляйте исходный текст body без агрессивной фильтрации, чтобы не потерять смысл.
Совет: при импорте новых отзывов сохраняйте первичный JSON в поле source_raw, это упростит отладку.
✅ Проверка: в файле data/reviews_clean.csv нет пустых строк и явных повторов.
Возможные проблемы: кодировка символов. Решение: используйте utf-8 по умолчанию и проверяйте вывод в CSV.
Шаг 8: AI‑анализ тональности (sentiment) и темы жалоб
Цель
Автоматически определить тональность каждого отзыва и выделить ключевые темы для быстрой реакции.
Пошаговая инструкция
- Установите зависимости, если пропустили ранее: pip install torch --index-url https://download.pytorch.org/whl/cpu; pip install transformers sentencepiece scikit-learn
- Подготовьте однофайловый скрипт анализа. Команда: echo import sqlite3,pandas as pd,math,json,datetime; from transformers import AutoTokenizer,AutoModelForSequenceClassification,TextClassificationPipeline; import numpy as np; m='cointegrated/rubert-tiny-sentiment-balanced'; tok=AutoTokenizer.from_pretrained(m); mdl=AutoModelForSequenceClassification.from_pretrained(m); pipe=TextClassificationPipeline(model=mdl,tokenizer=tok,framework='pt',device=-1,return_all_scores=False); c=sqlite3.connect('reviews.db'); df=pd.read_sql_query('select review_id, body from reviews',c); def lab(x): r=pipe(x[:450]) if x else [{'label':'neutral','score':1.0}]; return r[0]['label'], float(r[0]['score']); res=[(rid,)+lab(txt) for rid,txt in df.values]; for rid,label,score in res: c.execute('alter table reviews add column if not exists sentiment text'); c.execute('alter table reviews add column if not exists sentiment_score real'); c.execute('update reviews set sentiment=?, sentiment_score=? where review_id=?',(label,score,rid)); c.commit(); c.close(); print('sentiment done') > sentiment_ai.py
- Запустите: python sentiment_ai.py. Скрипт скачает модель и заполнит поля sentiment и sentiment_score.
- Проверьте заполнение: python -c "import sqlite3; c=sqlite3.connect('reviews.db'); print(c.execute('select sentiment, count(*) from reviews group by sentiment').fetchall()); c.close();".
Важные моменты: модель загружается один раз и может занять несколько сотен мегабайт и несколько минут времени. Это нормально. Оценка идёт по усечённому тексту, чтобы ускорить работу.
Совет: если вы регулярно анализируете большие объёмы, выполняйте sentiment ночью по расписанию, чтобы не мешать рабочим задачам.
✅ Проверка: в базе у каждой записи появились поля sentiment и sentiment_score, а сводка по запросу показывает три класса: positive, neutral, negative.
Возможные проблемы: память переполнена при большой выборке. Решение: анализируйте батчами по 500–1000 отзывов, выбирая их порциями через limit и offset.
Шаг 9: Отчёты и метрики: CSV, сводки и ключевые графики
Цель
Создать понятные отчёты для команды: динамика оценок, доля негативных отзывов, частые проблемы по словам.
Пошаговая инструкция
- Сформируйте сводку по оценкам. Команда: python -c "import sqlite3,pandas as pd; c=sqlite3.connect('reviews.db'); df=pd.read_sql_query('select product_id, rating, sentiment, created_at from reviews',c); df['created_at']=pd.to_datetime(df['created_at'],errors='coerce'); df['date']=df['created_at'].dt.date; piv=df.groupby(['product_id','date'])['rating'].mean().reset_index().rename(columns={'rating':'avg_rating'}); piv.to_csv('data/avg_rating_by_day.csv',index=False); neg=df[df['sentiment']=='negative'].groupby(['product_id','date']).size().reset_index(name='neg_count'); neg.to_csv('data/negative_by_day.csv',index=False); c.close(); print('reports ready')".
- Сделайте частотный словарь проблемных слов в негативных отзывах. Команда: python -c "import sqlite3,re,collections; c=sqlite3.connect('reviews.db'); cur=c.cursor(); rows=cur.execute('select body from reviews where sentiment="negative"').fetchall(); words=collections.Counter(); stop=set(['и','в','на','не','что','это','как','с','к','по','из','за','у','от']); [words.update([w for w in re.sub(r'[^а-яa-z0-9 ]',' ',(r[0] or '').lower()).split() if w not in stop and len(w)>2]) for r in rows]; top=words.most_common(50); open('data/top_negative_words.csv','w',encoding='utf-8').write('word,count\n'+'\n'.join([f'{w},{c}' for w,c in top])); c.close(); print('keywords ready')".
- Соберите общий CSV для передачи в BI систему: python -c "import sqlite3,pandas as pd; c=sqlite3.connect('reviews.db'); df=pd.read_sql_query('select * from reviews',c); df.to_csv('data/reviews_full_export.csv',index=False); c.close(); print('full export')".
Важные моменты: даты могут быть пустыми или в разных форматах. Мы пытаемся привести их к единому типу, но иногда понадобится ручная корректировка.
Совет: откройте data/avg_rating_by_day.csv и data/negative_by_day.csv в любой BI системе или даже в Excel, постройте линию тренда по каждому SKU. Это быстрый и наглядный способ увидеть проблемы.
✅ Проверка: в папке data появились три CSV файла с ожидаемым содержимым. В них корректные заголовки и понятные числа.
Возможные проблемы: пустые даты ломают группировку. Решение: замените пустые created_at на дату загрузки scrape_ts при экспорте.
Шаг 10: Автоматизация и расписание задач
Цель
Запускать сбор отзывов и аналитическую обработку по расписанию без участия человека.
Пошаговая инструкция
- Создайте командный сценарий для обновления отзывов. Пример на Windows PowerShell: echo $urls=Import-Csv source_list.csv; foreach ($u in $urls) { python scraper_basic.py --marketplace=$u.marketplace --product=$u.product_id --url=$u.url --delay=1.5 } ; python sentiment_ai.py ; python -c "import sqlite3,pandas as pd; c=sqlite3.connect('reviews.db'); df=pd.read_sql_query('select count(*) as n from reviews',c); print(df.to_string(index=False)); c.close()" > run_all.ps1.
- Запланируйте ежедневный запуск в Планировщике заданий Windows. Создайте задачу, укажите программу PowerShell и путь к скрипту run_all.ps1. Выберите время вне пиковых часов.
- На macOS и Linux используйте cron. Добавьте строку в crontab: 0 2 * * * cd /путь/к/reviews_automation && .venv/bin/python sentiment_ai.py.
- Проведите тестовый ручной запуск вашего расписания. Убедитесь, что база обновилась и отчёты пересчитались.
Важные моменты: на серверах иногда отключают спящий режим. Убедитесь, что компьютер включён в назначенное время или используйте облачный сервер.
Совет: добавьте уведомление об успехе или ошибке в конце сценария. Например, выводите итоговое число отзывов и сохраняйте лог в файл.
✅ Проверка: после планового запуска число отзывов растёт, а CSV отчёты обновляются с новой датой модификации файла.
Возможные проблемы: задача не запускается из‑за прав доступа. Решение: запустите планировщик от имени администратора и проверьте путь к интерпретатору Python внутри виртуального окружения.
Проверка результата
Чек‑лист: у вас создана база reviews.db; работают оба сценария сбора (для статичных и динамичных страниц); в базе есть отзывы не менее чем по 5 товарам; настроен sentiment; сформированы отчёты CSV; расписание выполняется автоматически; блокировок нет или они редки и обрабатываются повторами.
Как протестировать: удалите временно 2–3 записи и пересоберите их заново, проверив, что дубликаты не появляются. Откройте CSV с рейтингами и сравните с реальной страницей товара по нескольким датам. Проверьте, что негативные отзывы действительно содержат жалобы.
Показатели успеха: точность извлечения полей выше 95 процентов на выборке из 100 отзывов; доля дубликатов менее 1 процента; время обновления 500 карточек менее 1 часа при безголовом браузере или менее 15 минут при API; корректность sentiment на уровне здравого смысла для 8 из 10 отзывов.
Типичные ошибки и решения
- Проблема: парсер ничего не находит. Причина: селекторы не соответствуют текущей верстке. Решение: обновите селекторы по актуальному HTML.
- Проблема: появляются дубликаты. Причина: нестабильный review_id. Решение: используйте хэш по автору, дате и тексту или нативный id отзыва.
- Проблема: частые блокировки. Причина: высокая скорость запросов, без прокси. Решение: добавьте ротацию прокси и задержки 1.5–3.5 секунды.
- Проблема: пустые даты ломают отчёты. Причина: нет поля created_at в источнике. Решение: используйте scrape_ts в качестве даты.
- Проблема: AI‑анализ падает с ошибкой памяти. Причина: слишком большой батч. Решение: обрабатывайте по 500 записей и ограничивайте длину текста.
- Проблема: расписание не запускается. Причина: неверный путь к Python окружению. Решение: укажите абсолютный путь к интерпретатору внутри .venv.
- Проблема: странные символы в CSV. Причина: другая кодировка. Решение: всегда сохраняйте в utf-8 и открывайте файл с этой кодировкой.
Дополнительные возможности
Продвинутые настройки: добавьте асинхронный сбор через aiohttp для ускорения статичных запросов; примените очереди задач (например, Celery) для масштабирования; для хранилища используйте PostgreSQL, если данных больше миллиона строк.
Оптимизация: кэшируйте ответы запросов на 24 часа, чтобы не перегружать площадку; обрабатывайте обновления инкрементально — запрашивайте только последние N страниц или новые с конца; добавьте тонкую категорию тональности: очень негативный, умеренно негативный, нейтральный, умеренно позитивный, очень позитивный, обучив пороги на ваших данных.
Что ещё можно сделать: добавьте извлечение тем через ключевые фразы LDA или KeyBERT; создайте простой веб‑дашборд на Streamlit или другой системе; прикрутите алёрты — отправку письма при росте негатива выше заданного порога; добавьте кластеризацию проблем по словам и по продуктам.
Совет: храните конфигурацию проекта в отдельном JSON файле: прокси, задержки, пути к отчётам, список SKU. Это ускорит перенос на другие машины.
⚠️ Внимание: не пытайтесь обходить капчи и технические защиты. Если площадка активно защищается, переходите на официальный API или снижайте частоту запросов.
FAQ
- Как начать, если я не умею программировать? Ответ: следуйте командам дословно, не меняйте синтаксис. Начните с 1–2 источников и базового скрипта.
- Можно ли собирать отзывы из мобильного приложения маркетплейса? Ответ: обычно нет, это нарушает условия. Используйте веб‑страницы или официальные API.
- Как ускорить сбор? Ответ: используйте асинхронные запросы для API источников и ограничьте одновременные соединения до 3–5 на домен, добавьте кэш.
- Что делать, если модель sentiment ошибается? Ответ: добавьте пороги уверенности и подсветку сомнительных отзывов для ручной проверки, либо дообучите модель на ваших примерах.
- Как обновлять только новые отзывы? Ответ: храните последний известный review_id или дату и запрашивайте только последние страницы, прекращая сбор при встрече уже известного id.
- Как решить проблему блокировок IP? Ответ: используйте платные надёжные прокси с ротацией, уменьшите частоту, добавьте паузы и разные user-agent.
- Где хранить большие массивы? Ответ: используйте PostgreSQL или облачные базы. Для начала достаточно SQLite, но при росте переходите на серверную БД.
- Можно ли объединять отзывы с нескольких площадок? Ответ: да, если поля согласованы. Используйте поле marketplace для различения и общий product_id или SKU‑маппинг.
- Как протестировать на законность? Ответ: проверьте публичность страниц, robots.txt, условия использования, не собирайте персональные данные и ограничьте частоту.
- Что делать, если структура страницы изменилась? Ответ: обновите селекторы, добавьте мониторинг ошибок и тест, который ежедневно проверяет наличие ключевых блоков.
Заключение
Вы прошли полный путь: выбрали источники, настроили окружение, спроектировали схему данных, собрали отзывы с помощью HTTP и Playwright, настроили ротацию прокси и задержки, очистили и нормализовали данные, провели AI‑анализ тональности и сформировали отчёты. Теперь ваша система способна автоматически обновлять данные по расписанию, а команда получает понятные метрики и быстрые инсайты.
Что делать дальше: расширяйте список источников, добавляйте отчёты по ключевым словам и темам, внедряйте алёрты при росте негативных отзывов. По мере роста проекта переходите на PostgreSQL и разносите сбор и аналитику по контейнерам.
Куда развиваться: изучите асинхронный парсинг, очереди задач, оркестраторы вроде Airflow, а также тематическое моделирование и дообучение языковых моделей на ваших данных. Так вы превратите мониторинг отзывов в систему раннего предупреждения и постоянного улучшения качества продукта.
Совет: документируйте каждую настройку и храните образцы команд в одном файле. Это сэкономит часы времени при переносе и масштабировании.
